https://www.acmicpc.net/problem/2186
2186번: 문자판
첫째 줄에 N(1 ≤ N ≤ 100), M(1 ≤ M ≤ 100), K(1 ≤ K ≤ 5)가 주어진다. 다음 N개의 줄에는 M개의 알파벳 대문자가 주어지는데, 이는 N×M 크기의 문자판을 나타낸다. 다음 줄에는 1자 이상 80자 이하의
www.acmicpc.net
안녕하세요, 이륙사입니다.
풀이
위 문제는 DFS를 사용하는 그래프 탐색 문제였습니다. 하지만 골드3에 정답률이 20퍼센트대인 것을 보아, 기본적인 DFS 문제와는 조금 다르다는 것을 짐작할 수 있는데요.
움직일 수 있는 경우의 수
먼저, 특정 위치에서 상하좌우로 한 칸씩 이동하는 것이 아니라 k칸씩 이동이 가능합니다. 즉, 아래 그림의 X표시된 곳으로 한번에 점프해서 이동할 수 있습니다. 따라서 k <= 5이므로, 매 위치마다 4 * 5 = 최대 20가지의 움직임이 가능합니다.

중복 방문
또 특이한 점은 갔던 곳을 다시 갈 수 있다는 것입니다. 중복해서 방문할 수 있기 때문에 현재 조건만 봐선 DFS가 아니라 매 위치마다 방문 가능한 모든 곳을 탐색하는 brute force 문제로 보는게 더 정확할 것 같습니다.
그럼 전부 확인하면서 풀 수 있을지 알아보기 위해 시간 복잡도를 계산해보겠습니다.
- 최대 노드 개수 = N * M = 10,000개,
- 매 위치마다 방문을 고려할 가지수 = 20개
- 단어 길이 <= 80
최대 80번을 움직이는데 한 번 움직일 때마다 20곳을 고려해야 하므로, 10,000 * 20 ^ 80 = 100자리가 넘는 수가 나옵니다. 따라서, 전부 확인하는 방식으로는 시간안에 해결할 수가 없습니다. 그러면 어떻게 시간을 단축시킬 수 있을까요?
📌3차원 그래프
2차원 그래프가 주어졌지만, 사실은 3차원 그래프로 생각할 수 있습니다. 같은 위치를 방문하더라도 영단어의 몇 번째 인덱스에 쓰였느냐에 따라 다른 노드로 볼 수 있기 때문입니다.
예) 단어: "ABAB", K = 2
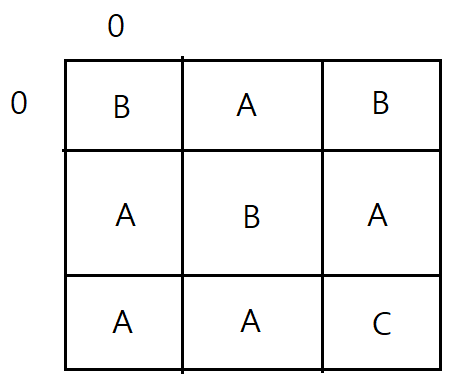
ABAB를 찾고 있고, (0, 1)에서 탐색을 시작하는 상황을 가정해보겠습니다. 그러면 B인 (0, 0), (0, 2), (1, 1)로 갈 수 있는데, (0, 0)으로 가보겠습니다. K=2이므로, (0, 1), (1, 0), (2, 0)으로 갈 수 있습니다. 그리고 문제의 중복 상황인 (0, 1)로 다시 가보겠습니다. (0, 1) -> (0, 0) -> (0, 1)이 됐습니다. 여기서 3개의 B로 갈 수 있으므로 3개의 ABAB 경로를 찾을 수 있습니다. 즉, (0, 1)을 ABAB의 3번째 순서(인덱스 2)로 방문하면 언제나 3개의 경로를 찾을 수 있다는 뜻입니다. 이것을 기록해놓으면 (1, 2) -> (0, 2) -> (0, 1)의 경로로 탐색을 할 경우 3개의 B에 다시 방문하지 않더라도 3개의 경로가 있다는 것을 바로 알 수 있습니다. => 메모이제이션
경로를 못찾았던 위치도 마찬가지로 0을 기록해서 해당 위치를 특정 순서로 방문하면 더이상 탐색하지 않을 수 있습니다.
쉽게 말하면 같은 (0, 1)의 A를 방문하더라도 이것을 ABAB[0]으로 사용했는지 ABAB[2]로 사용했는지에 따라 다른 노드가 되는 것입니다. 우리가 같은 방안에 있더라도 그 날짜가 오늘이었는지 어제였는지에 따라 다른 상태라고 생각하면 이해하기 편할 것 같네요.
따라서 이 문제는 [행][열][인덱스]로 구성된 3차원 그래프 DFS + 다이나믹프로그래밍 혹은 DFS + 메모이제이션 문제였습니다.

※ BFS를 사용하면 큐에 너무 많은 데이터가 들어가서 메모리 초과가 난다고 하네요!
※ 각 위치를 노드로 표현해보면 Node(문자, 행, 열, 인덱스)로 할 수 있습니다.
생각 과정
- 영단어 경로를 찾기 조건을 만족하는 노드들을 방문하는 그래프 탐색문제라는 것을 확인한다.
- 특정 위치에서 이동 가능한 경우의 수와 중복 방문이 가능하다는 것을 확인하고, 완전 탐색으로 풀었을 때의 시간 복잡도를 계산해본다.
- 시간 복잡도가 정말 크다. 복잡도를 줄이기 위한 추가 고려 사항을 생각해본다.
- 특정 노드를 방문하더라도 단어의 몇 번째 문자를 확인하느냐에 따라 node state가 다르다는 것을 이해한다.
- 따라서 index까지 고려하는 3차원 그래프 탐색문제이다. 중복 방문 처리가 가능하기 때문에 시간을 단축시킬 수 있다.
코드
import java.io.BufferedReader
import java.io.InputStreamReader
import java.util.*
var answer = 0
var rowSize = 0
var colSize = 0
lateinit var target: CharArray // 찾으려는 영단어 문자 배열
lateinit var board: Array<CharArray> // 2차원 그래프
val dNext = mutableListOf<Pair<Int, Int>>()
lateinit var visited: Array<Array<IntArray>> // 3차원 그래프 -> [row][col][몇번째에 도착했는지]
fun main() = with(BufferedReader(InputStreamReader(System.`in`))) {
val st = StringTokenizer(readLine())
rowSize = st.nextToken().toInt()
colSize = st.nextToken().toInt()
val moveLimit = st.nextToken().toInt()
board = Array<CharArray>(rowSize) {
readLine().toCharArray()
}
target = readLine().toCharArray()
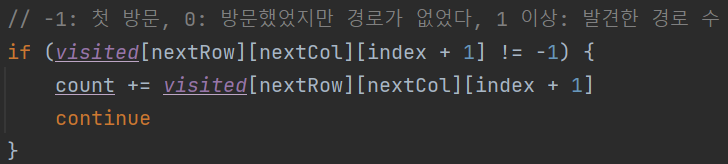
// -1: 첫 방문, 0: 방문했었지만 경로가 없었다, 1 이상: 발견한 경로 수
visited = Array(rowSize) {
Array(colSize) {
IntArray(target.size) { -1 }
}
}
// 상하좌우 K칸 이동 경우의 수
for (i in 1..moveLimit) {
val up = Pair(-i, 0); val down = Pair(i, 0)
val left = Pair(0, -i); val right = Pair(0, i)
dNext.addAll(listOf(up, down, left, right))
}
// 모든점을 시작점으로 탐색
for (i in 0 until rowSize) {
for (j in 0 until colSize) {
if (board[i][j] == target[0]) {
answer += findRouteCount(i, j, 0)
}
}
}
print(answer)
}
fun findRouteCount(row: Int, col: Int, index: Int): Int {
if (index == target.size - 1) { // 단어를 찾았다
return 1
}
var count = 0 // 지금 위치에서 찾을 수 있는 경로 수를 저장할 변수
for (i in dNext.indices) {
val nextRow = row + dNext[i].first
val nextCol = col + dNext[i].second
if (nextRow !in 0 until rowSize || nextCol !in 0 until colSize) continue
if (board[nextRow][nextCol] != target[index + 1]) continue // 그래프 범위 밖
// 이전에 방문한 곳일 경우
if (visited[nextRow][nextCol][index + 1] != -1) {
count += visited[nextRow][nextCol][index + 1]
continue
}
count += findRouteCount(nextRow, nextCol, index + 1)
}
// 경로를 찾지 못했으면 0, 찾았으면 0보다 큰 수가 저장된다
visited[row][col][index] = count
return count
}'Problem Solving > 백준' 카테고리의 다른 글
| 백준 3108번: 로고 (Kotlin) (0) | 2022.01.18 |
|---|---|
| 백준 1525번: 퍼즐 (Kotlin) (0) | 2022.01.17 |
| 백준 13164번: 행복 유치원 (Kotlin) (0) | 2022.01.15 |
| 백준 22862번: 가장 긴 짝수 연속한 부분 수열 (large) (Kotlin) (0) | 2022.01.14 |
| 백준 1697번: 숨바꼭질 (Kotlin) (0) | 2022.01.11 |

