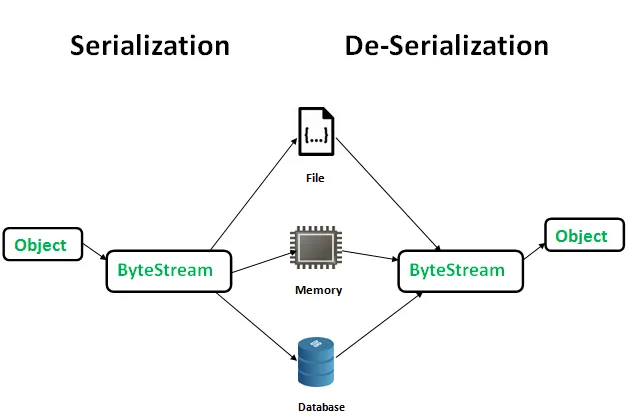
scope 함수는 특정 객체에 대한 일시적인 스코프(코드 블록)를 생성해서 그 객체와 관련된 작업을 수행하는 함수이다.
목적은 코드를 더 간결하게 만드는 것에 있다.
사용 예시
아래 코드는 스코프 함수인 let을 사용하고 있다.
Person("Alice", 20, "Amsterdam").let {
println(it)
it.moveTo("London")
it.incrementAge()
println(it)
}
살펴보면, 객체의 확장 함수 형태로 함수 let을 호출하고 있으며, let은 람다를 인자로 받는다.
람다는 수신 객체(Person)를 인자로 받아서 작업을 수행하는 블록이며, it으로 수신 객체에 접근하고 있다.
참고로 스코프 함수를 호출할 때 사용하는 객체를 수신 객체, 수신자, context object 등으로 표현하는데, 나는 수신 객체가 편해서 그렇게 부르고 있다.
let을 사용하지 않은 코드
val alice = Person("Alice", 20, "Amsterdam")
println(alice)
alice.moveTo("London")
alice.incrementAge()
println(alice)
위 코드는 let을 사용하지 않게 바꾼 것이다. 솔직히 이 예시만 봐선 간결해졌는지 잘 모르겠다. 하지만, alice 객체를 사용하는 작업들을 하나로 묶었다는 점은 확실히 눈에 들어온다!
Scope 함수의 종류
스코프 함수에는 let, run, also, apply, with 5개가 있는데, 함수마다 호출 형식에 약간의 차이가 있다. 그 차이를 아래에 표로 첨부했다. 눈에 잘 안 들어온다면 우선 스킵하고 그 아래의 함수 소개로 고고.
| 함수 | 객체 참조 | 리턴 값 | 확장 함수인가? |
| let | it | 람다 리턴 값 | Yes |
| run | this | 람다 리턴 값 | Yes |
| run | 없음 | 람다 리턴 값 | NO (객체 없이 호출) |
| with | this | 람다 리턴 값 | NO (인자로 객체 전달) |
| apply | this | 수신 객체 | Yes |
| also | it | 수신 객체 | Yes |
함수의 호출 형태에서 구분되는 요소는 3가지이다
- 객체 참조: 수신 객체의 참조를 this로 하는가, it으로 하는가
- 리턴 값: 리턴 값이 람다의 반환 값인가, 수신 객체 자체인가?
- 호출 형태: 확장 함수로 호출하는가, 일반 함수처럼 호출 하는가?
1. let
fun <T, R> T.let(block: (T) -> R): R
let은 객체(T)의 확장 함수 형태로 사용된다. 함수의 인자로 람다 블록을 입력 받는데, 람다는 자기 자신(T)을 받아서 R을 반환하며, 람다 안에서 T는 it으로 접근 가능하다. let은 최종적으로 람다의 반환 값 R을 리턴한다.
chain operation에서 사용
val numbers = mutableListOf("one", "two", "three", "four", "five")
numbers.map { it.length }.filter { it > 3 }.let {
println(it)
}
// vs
val resultList = numbers.map { it.length }.filter { it > 3 }
println(resultList)
위와 같이 chain operation의 끝에서 값을 받아서 최종 결과를 만들어 내는 형태로 사용할 수 있다.
그 아랫 줄의 코드는 같은 상황에서 let을 사용하지 않는 경우이다. 한 줄이라서 어떻게 해도 가독성에 차이는 없어 보이지만, let에 들어갈 코드가 많아진다면 let 사용문이 좀 더 간결하게 느껴질 것 같다.
객체가 non-null 일 경우의 작업에 사용
let을 가장 많이 활용하는 형태이다. nullable 객체에 대해 non-null일 경우에 수행할 작업을 정의할 수 있다.
또한, 블록 안에서 non-null로 casting되어서 !!이나 ? 없이 접근할 수 있다.
val str: String? = "Hello"
val str2: String? = null
val length = str?.let { it.length }
val length2 = str2?.let { it.length }
val length3 = str2?.let { it.length } ?: 0
print(length) // 5
print(length2) // null
print(length3) // 0
- str가 null이 아니므로, length에는 람다의 결과 값인 str의 length가 할당된다.
- str2는 null이기 때문에 let 함수가 실행되지 않고 null을 반환한다. elvis(?:) 연산자로 null일 때의 처리를 해줄 수도 있다.
2. with
fun <T, R> with(receiver: T, block: T.() -> R): R
with는 let과 달리 일반 함수 형태로 사용된다. 객체 T를 인자로 받아서 임의의 결과 값 R을 반환하는 람다를 입력 받으며, 함수의 최종 결과로 람다의 반환 값 R을 반환한다.
람다에서 받는 객체 T를 보면 T.() 라고 되어 있는데, 이렇게 받으면 확장 함수와 같이 처럼 this로 T에 접근할 수 있다. 또한, this 없이도 T의 멤버에 접근할 수도 있다.
단순히 함수를 호출하는 경우 or 함수 호출을 그룹화 하는 경우
val numbers = mutableListOf("one", "two", "three")
with(numbers) {
println("인자 $this로 with를 호출했다.")
println("이것은 $size개의 원소를 갖고 있다.")
}
with(viewModel) {
dataA.observe(viewLifecycleOwner) {
// ...
}
this.dataB.observe(viewLifecycleOwner) {
// ...
}
}
공식 문서에 따르면 객체의 메서드의 결과 값이 필요하지 않고 호출만 하는 경우에 사용하길 추천하고 있다.
특히, 객체의 여러 함수를 호출할 때 보기 좋게 모아두는 용도로 사용할 수 있다.
값을 계산하기 위한 helper 객체로 활용하는 경우
val firstAndLast = with(numbers) {
"FirstElement is ${first()}, the last is ${last()}"
}
println(firstAndLast)
어떤 객체를 활용해서 값을 계산하고, 결과 값이 필요할 때 사용할 수 있다.
3-1. run (extension)
fun <T, R> T.run(block: T.() -> R): R
run은 확장 함수 형태로 호출된다. 람다 블록은 자신을 T.()로 입력 받기 때문에 this로 접근 가능하고, 임의의 결과 R을 반환한다.
확장 함수로 호출한다는 점을 제외하면 with와 완전히 같지만, 확장 함수 방식 덕분에 null-safe(?.)호출이 가능하다. (object?.run())
객체를 초기화하고 값을 계산하는 경우
val service = MultiportService("<https://example.kotlinlang.org>", 80)
val result = service.run {
port = 8080
query(prepareRequest() + " to port $port")
}
// with을 활용한 같은 코드
val letResult = with(service) {
port = 8080
query(it.prepareRequest() + " to port ${it.port}")
}
run은 this로 객체 접근이 가능하고 결과 값을 반환하므로, 객체를 초기화 하고 그것으로 값을 계산하는 상황에서 사용하는 것을 공식 문서에서 권장하고 있다.
그 아래는 with로 같은 상황의 코드를 작성한 것이다. 큰 차이가 없어서 앞으로 뭘 사용해야 가독성이 나아질지 고민될 것 같다. with는 읽었을 때 “T객체로 ~~작업을 합니다” 라는 의미가 있어서 개인적으로 객체를 초기화 하는 내용이 있된다면 run이 조금 더 적절할 것 같다.
3-2. run (not extension)
fun <R> run(block: () -> R): R
run은 수신 객체 없이 함수만 호출하는 한 가지의 형태가 더 있다. 입력 받는 람다는 매개 변수 없이 반환 값 R만 존재한다. 함수의 최종 결과는 람다의 R을 반환한다.
여러 중간 값과 함수 호출을 거쳐서 최종 결과를 계산하는 경우
val hexNumberRegex = run {
val digits = "0-9"
val hexDigits = "A-Fa-f"
val sign = "+-"
Regex("[$sign]?[$digits$hexDigits]+")
}
위 코드는 Regex 객체를 초기화 하고 있다. 그 과정에서 몇 개의 중간 값들을 통해 최종 객체를 생성하는데, 이런 과정을 run 블록으로 묶어 가독성을 높일 수 있다.
4. apply
fun <T> T.apply(block: T.() -> Unit): T
apply는 확장 함수로 호출되며, 람다에서 수신 객체를 인자로 입력 받는다. 하지만 let, with, run과 다르게 람다에 반환 값이 없고 함수의 최종 결과로 수신 객체 T를 다시 반환한다. 람다의 매개변수 타입이 T.()이므로 this로 수신 객체에 접근한다. ****
객체를 초기화(설정 변경) 하는 경우
val adam = Person("Adam").apply {
age = 32
city = "London"
}
this로 멤버에 쉽게 접근 가능하고 자기 자신을 리턴하기 때문에 객체의 초기화나 설정을 변경할 때 유용하다.
5. also
fun <T> T.also(block: (T) -> Unit): T
apply처럼 확장 함수로 호출되고 수신 객체를 다시 리턴한다. apply와 달리 람다에서 (T)로 수신 객체를 받아서 it으로 접근한다.
객체를 부가적으로 활용해서 다른 작업을 할 때 (ex 함수 인자로 사용)
val numbers = arrayListOf("one", "two", "three")
numbers
.also { println("add 하기 전에 print: $it") }
.add("four")
수신 객체를 위한 작업보다 수신 객체를 이용한 다른 작업을 할 때 사용하는 것이 권장된다. 함수의 이름처럼 ***“아, 그리고 ~~한 작업도 함께 해라”***라고 해석할 수 있다. ******
함수별 용도
이 함수는 반드시 이런 상황에서만 써야 해! 이런 건 없지만, 공식 문서에서 권장하는 함수별 이용 상황을 다시 정리해보면 다음과 같다.
- let
- non-null 객체에 대한 작업을 수행
- chain operation의 마지막에 사용하여 가독성 향상
- with
- 객체의 함수 호출을 그룹핑 and 결과 값이 필요하지 않을 때
- run
- 객체의 설정을 변경하고 그것을 활용한 연산 결과를 반환
- 하나의 작업이지만 여러 중간 값과 함수 호출이 필요할 때 한 블록으로 모아서 가독성 향상
- apply
- 객체의 설정 변경 (ex: 프로퍼티 초기화)
- also
- 객체를 타겟팅한 작업이 아니라 객체를 활용한 다른 작업을 수행 (ex 함수 인자로 사용)
참조
'TIL' 카테고리의 다른 글
| [Kotlin] Sequence (feat. 중간 객체, 지연(lazy) 연산) (0) | 2023.07.16 |
|---|---|
| [Kotlin] 람다(lambda)란 무엇이고 왜 사용하는 걸까? (0) | 2023.06.14 |
| (2) SOLID 원칙 정리 (객체 지향 프로그래밍) (0) | 2023.04.05 |
| (1) 의존성 주입(Dependency Injection, DI)이란? - 개념과 장점 (0) | 2023.04.03 |
| [Android] ViewPager2 좌우 미리 보기 + 페이지 확대/축소 애니메이션 구현 기록 (0) | 2023.03.15 |