Context란
Context는 안드로이드 시스템에 대한 인터페이스 역할을 하는 객체이다.
흠…?
좀 더 쉽게 풀어보면, Context는 어플리케이션 리소스, 파일, 시스템 서비스 등에 접근할 수 있는 메소드들을 갖고 있다. 그래서 앱의 resources나 File과 같은 시스템 자원에 접근하거나 새로운 Activity 실행, Intent 수신과 같이 애플리케이션 레벨의 작업을 요청할 수 있다.
또한, Context는 추상 클래스이며 구현체는 안드로이드 시스템에 의해 제공된다
Context 쓰임 정리
- 앱의 리소스에 접근: res, assets, internal storage
- 컴포넌트 통신: 액티비티 시작, Intent 수신 등
- 시스템 서비스에 접근: SystemServices
- 앱 정보에 접근: ApplicationInfo
- GUI 작업: ex: AlertDialog.Builder(requireContext())
실제로는 훨씬 다양한 상황에서 사용된다!
Context의 종류 (feat. 계층 구조)
Context의 클래스 계층 구조를 보면 재밌는 사실을 확인할 수 있다.
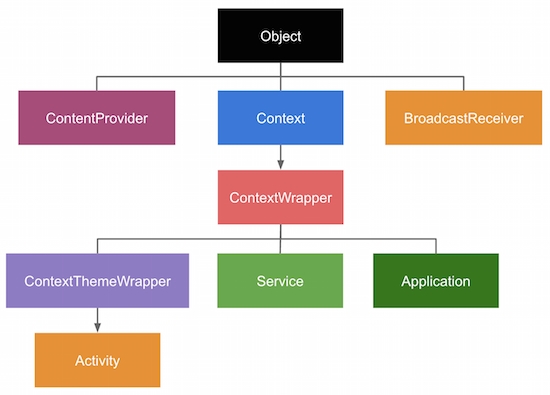
(1) Application, Service, Activity 모두 Context를 상속받고 있다. Activity가 Context 자리를 this로 대신할 수 있었던 이유가 이것이었다.
(2) Context는 Activity, Service, Application 등 종류가 나뉘어 있다.
앱 안에는 여러 Activity와 Service가 존재할 수 있으므로 Activity Context는 여러 객체가 있을 수 있다. 반면, Application은 하나라서 Singleton으로 앱 내에서 하나만 존재한다.
즉, Context는 종류가 나뉘며 각각이 다른 생명주기를 갖고 있다. 따라서, 올바르지 않은 Context를 사용할 경우 메모리 누수가 발생할 수 있다.
Context와 Memory Leak
Context는 크게 ApplicationContext와 나머지 Context, 그중에서도 Activity Context로 나눌 수 있다.
Application Context
ApplicationContext는 Applicaton 생명주기를 따르는 싱글턴 객체이다. 따라서, 앱 전역에서 사용될Context가 필요하다면 ApplicationContext를 사용하자. (ex: RoomDatabase 객체 생성, 싱글턴 객체 생성)
싱글턴(or 액티비티 생명주기를 넘어가는) 작업에 Activity Context를 사용할 경우 메모리 누수가 발생하므로 주의해야 한다! Activity가 종료되더라도 다른 객체에서 Activity를 Context로 참조하고 있다면 garbage collector가 메모리를 해제할 수 없기 때문이다.
Activity Context
Activity Context는 Activity의 생명주기에 종속되어 있다. 따라서, Activity 생명주기 내에서 사용될 Context가 필요하다면 Activity Context를 사용하는 것이 좋다.
특히, GUI 작업을 한다면 반드시 Application Context가 아닌 Acitivty Context를 사용해야 한다. (ex: 다이얼로그 생성, Toast 출력) 왜냐면 Acitivty의 Theme과 같은 고유한 정보는 해당 Context만이 갖고 있지 때문이다. 다른 Context를 사용할 경우 예상과 다른 결과를 보게 되거나 crash로 앱이 종료될 수도 있다.
정리
- 앱 전역에서 사용될 Context가 필요하다 → Application Context
- 액티비티 생명주기 내에서 or GUI 작업에 사용할 Context가 필요하다 → Activity Context
부록) Context를 가져오는 방법
1. Activity
액티비티가 Context 그 자체이므로, this로 Activity Context에 접근할 수 있다.
2. Fragment
context or requireContext 를 통해 Fragment를 hosting하는 Activity Context에 접근할 수 있다.
3. View
view.context 를 통해 View가 포함되어 있는 Activity의 Context에 접근할 수 있다.
4. ContentProvider
ContentProvider 클래스 안에서 context 를 통해 Application Context에 접근할 수 있다.
5. Application Context
각 Context에서 applicationContext을 통해 Application Context에 접근할 수 있다. (ex: context?.applicationContext)
정리
Context는 안드로이드 시스템과 통신할 수 있는 인터페이스로, 앱 리소스, 시스템 작업, 컴포넌트 통신 등을 요청할 수 있다.
Context는 크게 Applicaton Context와 Activity Context로 나눌 수 있는데, 상황에 적절한 것을 사용하지 않으면 메모리 누수나 앱 크래시가 발생한다. 앱 전역에서 사용된다면 Applicaton Context를, 액티비티 내에서 유효하거나 GUI 작업에 필요한 것이라면 Activity Context를 사용하자.
참조
- https://developer.android.com/reference/android/content/Context
- https://velog.io/@hanna2100/번역-안드로이드의-Context와-메모리누수
- https://medium.com/swlh/context-and-memory-leaks-in-android-82a39ed33002
- https://roomedia.tistory.com/entry/Android-Context란-무엇일까
- https://amitshekhar.me/blog/context-in-android-application
'TIL > 안드로이드' 카테고리의 다른 글
| [Android] Serializable vs Parcelable (0) | 2023.03.19 |
|---|---|
| [Android] 비트맵 크기 최적화 로딩하기 (0) | 2023.03.18 |
| [Android] Thread, Looper, Handler 기본 개념 (0) | 2023.03.16 |
| [TIL] 안드로이드 - Java와 Kotlin이 호환되는 이유 (0) | 2022.03.12 |